The NeoSmartML Foundation Model project aims to develop a comprehensive deep learning model that can extract, analyze, and predict various clinical outcomes from neonatal ICU monitor images captured through ESP32-CAM devices. Building upon existing work in fusion models and streaming data analysis, this project extends beyond basic risk classification to create a more versatile foundation model capable of multiple downstream tasks. Look here for earlier architecture: Machine learning-based decision-support.
This application will process real-time monitor images through OCR to extract vital signs data, combining temporal sequences with clinical context to provide various predictions and insights for neonatal care. The foundation model will serve as a base for multiple specialized tasks through fine-tuning or prompt engineering.
Model Architecture and Tasks:
The model will utilize a hierarchical architecture combining:
Vision encoder for raw monitor image processing
OCR processing layer for text extraction
Temporal sequence modeling for trend analysis
Multi-task prediction heads for various clinical outcomes
Target Classification Tasks:
Risk Level Assessment
Low, moderate, and high-risk classifications
Continuous risk probability scoring
Trend-based risk projection
Clinical Event Prediction
Apnea episodes
Bradycardia events
Desaturation events
Temperature instability
Treatment Response Prediction
Oxygen therapy effectiveness
Temperature intervention outcomes
Feeding tolerance
Medication response patterns
Physiological State Classification
Sleep/wake cycles
Stress levels
Pain assessment
Respiratory effort patterns
The deliverables of the project are as follows:
Develop a foundation model architecture that handles both image and temporal data
Create specialized prediction heads for multiple clinical tasks
Implement efficient model compression for edge deployment
Build an evaluation framework for model performance
Create documentation for model usage and fine-tuning
Develop integration guidelines for clinical applications
This foundation model will significantly advance the capabilities of neonatal monitoring systems by providing a versatile base model that can be adapted for multiple clinical tasks. The edge-optimized implementation ensures practical deployment in resource-constrained environments while maintaining high accuracy and real-time processing capabilities.
The model’s ability to handle multiple tasks through a single foundation architecture will improve efficiency and reduce computational overhead, while the attention-based mechanisms will help identify critical patterns in vital signs data. The project’s focus on interpretability and clinical integration ensures that the model’s predictions can be effectively utilized in clinical practice.
I’m interested in the NeoSmartML Foundation Model project for GSoC 2026 and come from a research background in Medical AI and clinical decision-support systems from the most premier institute of the India.
I wanted to ask:
Given the multi-task NICU prediction setup, are you envisioning a shared latent physiological representation with task-specific adapters for downstream heads?
How do you suggest applicants approach proposal drafting for this project, is there a preferred way to get early feedback or iterate on design choices before submission?
Also, similar to previous years, will there be any preliminary contribution/assignment expected prior to proposal evaluation?
Looking forward to have an interesting chat with you.
@mhtjsh Have you looked at the discussion from the earlier 2023 project that was linked?
Hi, thanks for your interest, your Medical AI background is a strong fit for this project.
On architecture: Yes, the vision is a shared latent physiological representation learned from fused sensor streams, with task-specific heads for downstream predictions (risk classification, event prediction, treatment response, etc.). We encourage you to propose your own architectural reasoning here: how you would handle asynchronous, poorly correlated vital sign streams at the embedding level and how you’d design the adapter/head structure would be strong differentiators in a proposal.
On proposal feedback: Start by thoroughly reviewing the prior work and architecture references in the project description. Then share a rough outline or specific design questions through our community discussion channel (linked on our GSoC org page). We’re open to iterating on proposals before the deadline. Early engagement is always better.
On preliminary tasks: Yes, there are expected contributions before proposal evaluation. They are listed in the project description:
Dynamically quantize the CheXNet model.
Integrate a rotation sensor motion detector into the app and display values dynamically.
Completing these is an important part of the evaluation process.
Yes, I’ve gone through the 2023 NeoRoo ML decision-support proposal. From that, I noticed that the preliminary tasks (like CheXNet quantization and motion sensor integration) were expected to as initial contribution pathway for the project.
But for the NeoSmartML FM project, I couldn’t find a similar explicitly defined preliminary task section. Could you please elaborate on what kind of starter contributions/tasks you would expect from applicants for this one? ( this information would be of great help if I missed noting it, which is already mentioned somewhere )
Furthermore, based on my current understanding, I was thinking of structuring the modeling pipeline along two possible directions:
One approach would be to first convert the ESP32-CAM monitor feed into structured temporal signals via OCR (HR, SpO₂, RR, Temp), followed by sequence formation over sliding windows. These sequences will be passed through a lightweight temporal encoder (something like, ConvLSTM or transformer-based) to capture short-term physiological correlations across async sampled vitals. The shared encoder output can be routed into task heads for continuous risk scoring and early prediction of apnea/bradycardia/desaturation events, with post-training quantization for deployment on edge hardware ( at last if required ).
Another direction could involve learning a joint representation directly from the monitor imagery itself. In this setup, a CNN-based visual encoder would extract both waveform morphology and numeric display regions, which can then be fused with OCR-derived values through a multimodal layer before temporal modeling with an attention-based sequence learner. The goal would be to build a shared latent state that supports downstream tasks such as treatment response estimation ( and look at downstream as completely separate as compared to encoding part and this would allow us to include more varied downstream tasks too, making it robust ), physiological state classification, or clinical event forecasting through fine-tuning, while still allowing model compression (e.g., QAT/pruning) for edge deployment.
Would this direction align with the intended scope for GSoC, or would it be preferable to stay closer to extending the older NeoRoo fusion-model style of work?
My name is Sagar, and I am a computer science student with a strong interest in AI/ML, particularly in healthcare and clinical decision-support systems. I have previously worked on machine learning projects such as a Chronic Kidney Disease prediction model and a computer vision–based driver drowsiness detection system, which involved working with medical-style risk prediction and real-time image analysis.
The NeoSmartML Foundation Model project closely aligns with my interests in multimodal medical AI, especially the combination of monitor image processing, OCR-based vital sign extraction, and temporal modeling for clinical outcome prediction. I am keen to learn more about designing a shared latent physiological representation for downstream tasks like risk assessment and event prediction.
I plan to review the prior NeoRoo architecture references and start working on the preliminary contribution tasks (CheXNet quantization and motion sensor integration) to better understand the codebase and system constraints.
I’m excited to engage with the community and would appreciate any guidance as I begin exploring this project.
My name is Anagha Pradeep, and I am a master’s student in computer science at Indiana University. I am new to open‑source health projects and would like to apply for GSoC 2026 with LibreHealth, focusing on the “NeoSmartML: Foundation Model for Neonatal ICU Monitor Data project."
From the project description, I understand that NeoSmartML aims to learn a shared representation from neonatal vital‑sign streams and then use separate heads for tasks like risk classification and event prediction. I am interested in exploring how to handle asynchronous and noisy vital‑sign signals and how to structure these task‑specific heads.
My background is in Python, software development, and machine learning, and I have written unit tests for application and data-processing code. I am comfortable reading existing code, adding tests, and improving documentation, and I want to grow by working on a real healthcare project.
Over the next few days, I plan to:
Read the prior work and architecture references linked in the project description.
Draft an initial architecture outline for NeoSmartML and share it here for feedback.
Start working on the suggested preliminary tasks (dynamic quantization of CheXNet and integrating a rotation‑sensor motion detector into the app).
If there are specific repositories or documents you think I should read first, I would be grateful for suggestions.
I am very excited by the interest in this project and the ideas put forth thus far. Looking forward to building on our initial work on NeoSmartML, and making tremendous progress this Summer!
My name is Rashmita Kudamala. I’m a graduate student in Health Informatics with a background in physiotherapy. My main interest is in applying machine learning to clinical and physiological data, especially for decision support systems.
I’ve been reading through the NeoSmartML project description and the discussion here. I’m really interested in the idea of learning a shared representation from neonatal ICU monitor data and then using separate heads for downstream tasks.
Since neonatal vital-sign data can be noisy and irregularly sampled, I’m curious how the current thinking is around handling that whether the plan is to use sequence models directly (like LSTM/Transformer-based approaches) or to explicitly model missingness and time gaps.
Over the next few days, I’ll go through the repository more carefully and try setting things up locally so I can understand the structure better and look for places to start contributing.
If there are specific parts of the codebase or references I should focus on first, please let me know.
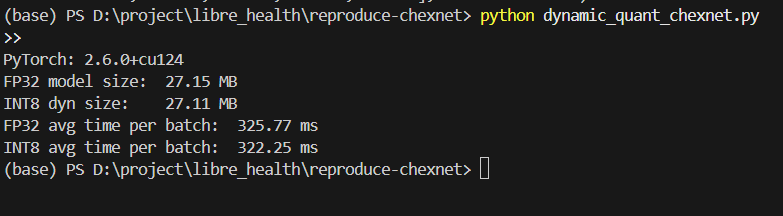
Measured model file size and CPU inference time for a batch of 8 images (3×224×224).
Results
FP32 model size: 27.15 MB
INT8 dynamic model size: 27.11 MB
FP32 avg CPU time per batch: ~325.8 ms
INT8 dynamic avg CPU time per batch: ~322.3 ms
So the improvement is very small.
My understanding (please correct me if wrong)
Dynamic quantization in PyTorch mainly quantizes Linear layers.
DenseNet‑121 (CheXNet) uses mostly convolution layers, so only the final classifier gets quantized.
That’s why the model size and speed don’t change much.
Questions
Are these steps and results okay for the preliminary “dynamic quantization” task?
For the main project, should I try more advanced methods (like static quantization or quantization-aware training that also include the convolution layers), or is it better to focus on something else?
Is there any existing LibreHealth/NeoRoo code related to quantizing medical CNNs that I should look at?
My name is Armel. I’m a medical doctor with a strong interest in digital health and AI applications in healthcare. I also work with Python and have experience building web-based systems. I’m excited to contribute to the NeoRoo project, starting with the preliminary task on dynamically quantizing the CheXNet model.
Before proceeding further, I’d like to confirm whether there is any existing LibreHealth or NeoRoo codebase related to CheXNet or medical CNN quantization that I should review first.
Looking forward to collaborating with you all. Thank you!
I’m interested in contributing to the NeoSmartML Foundation Model project for GSoC. I’ve been exploring the repository and recently submitted a couple of small merge requests while getting familiar with the OCR pipeline and codebase:
I’m also currently exploring the preliminary task related to dynamically quantizing the CheXNet model and trying to better understand the pipeline for extracting vitals from monitor images.
Could you please suggest which parts of the repository or components of the pipeline would be most helpful for new contributors to explore or improve first?
Looking forward to contributing more to the project.
as i introduced lately my self, may is Armel. I’m a medical doctor and Python developper, and i ame very interested in contributing to the NeoSmartML project as a part of Google Summer of code.
i recentely cloned the repository and set up the project locally in oder to better understand the current architecture and workflow. i have started exploring the different componenents of codebase, particularly the vitasocr module and camdatacapture backend, to understand how vita signs data are extracted and processed from monitor images.
in parallel, i ame currently working with OpenCV and EasyOCR to further familiarize myself with techniques for extracting data from monitor image such as heart rate, SpO2, etc; wich seems to be a key component of the project.
my goal is to actively contribute to the project while deepening my skills in computer vision and machine learning applied to medical data.
if there is any recommanded starting point or a good first issue that i could work on, particularly related to the Python(OCR pipeline), i would be happy ti get involved.
thank you for your time and for maintaining such inspiring project.
I’ve been exploring the NeoSmartML codebase and trying to understand the OCR
pipeline. While going through OCR_final.py, I noticed that the EasyOCR reader
was being initialized separately in each extraction function, so I tried
refactoring it to initialize once and share the results. I hope this is helpful:
Please let me know if I’ve missed anything or if the approach needs changes.
I’m also starting to look into the preliminary tasks now. For the CheXNet
dynamic quantization, I saw other contributor’s results showing minimal improvement
with dynamic quantization on DenseNet-121 since it’s mostly conv layers.
Should I explore static quantization or quantization-aware training as well,
or is the focus mainly on demonstrating the dynamic quantization workflow?
Any guidance on where to start would be really appreciated. Thank you!
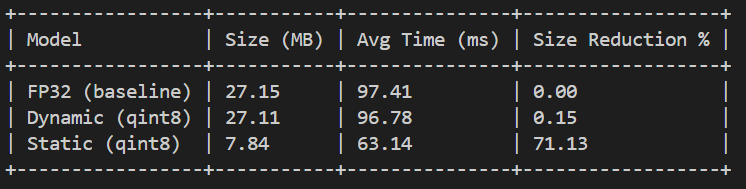
I’ve been working through the CheXNet dynamic quantization preliminary task.
I tried both dynamic and static quantization on DenseNet-121 (modified to
14 classes) and here’s what I got:
Dynamic quantization showed almost no improvement, which I think is because
DenseNet-121 is mostly conv layers and dynamic quantization mainly targets
Linear layers. So I tried static quantization as well, which brought the
size down quite a bit. I did get some warnings about mismatched quantization
parameters in DenseNet’s concat operations though, so I’m not sure how much
this affects accuracy. I haven’t tested that part yet.
I’m still learning my way through PyTorch quantization, so I’d appreciate
any feedback on whether this approach is on the right track, or if there’s
something I should be doing differently.
I’m Shima, a first-year computer science student just getting started in AI/ML for healthcare. I’ve built a diabetes disease prediction model using PyTorch. It gave me a hands-on feel for medical risk prediction and working with clinical tabular data.
NeoSmartML caught my attention because it sits at the intersection of everything I’ve been learning: OCR, temporal modeling, and multi-task clinical prediction. I still have a lot to learn, but I’ve read through the earlier NeoRoo ML architecture post and I’m actively working on the CheXNet quantization preliminary task. I’ll share the repo as soon as it’s ready.
Happy to receive any pointers from the community as I dig deeper into this!
I’m a Data Science student very interested in this project. Regarding the hierarchical architecture, are there specific vision encoders (like MobileNetV3) or quantization techniques the community prefers for edge deployment on ESP32-CAM? I’d like to understand the technical constraints before drafting my approach.