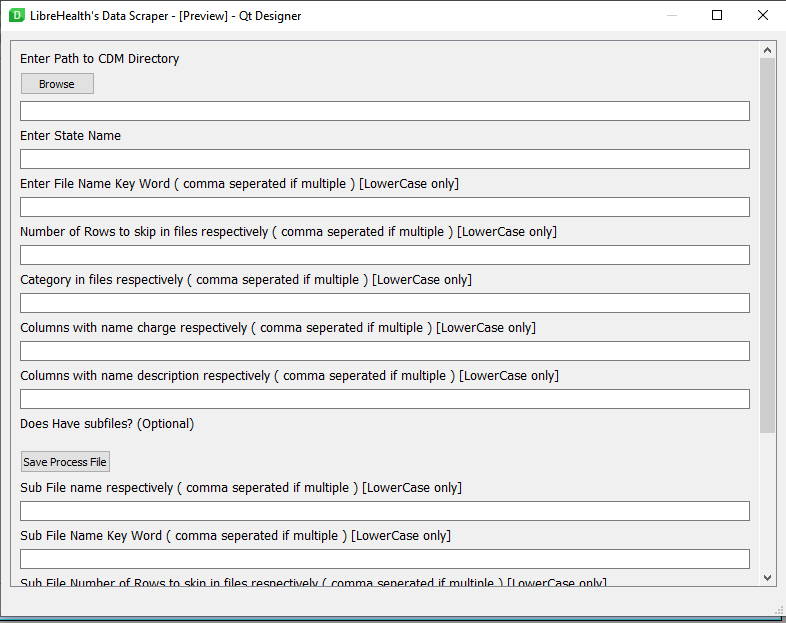
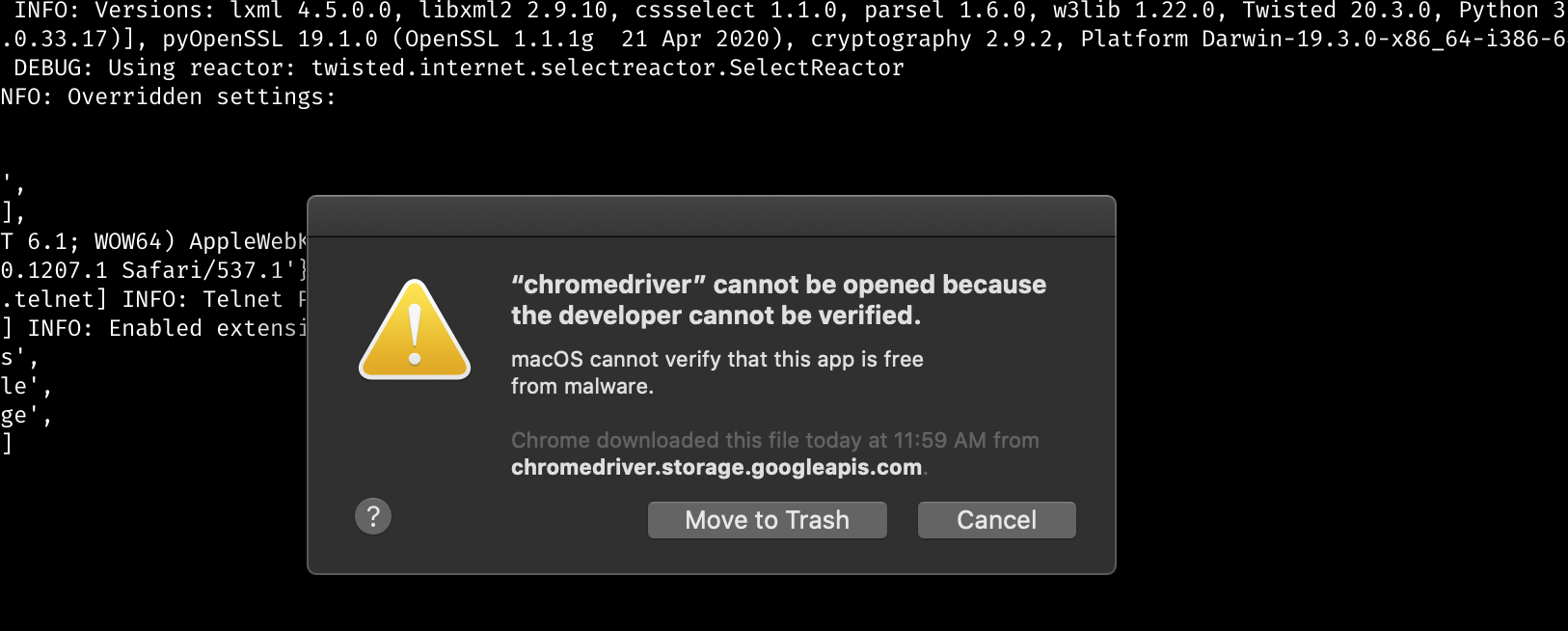
On testing the scrapper, I ran into a few issues that I could resolve but you should consider handling them
The chromium.exe is default windows and wont work on my system (MacOS) havent tried for Linux but I guess it won’t too… It kept on giving
start
os.path.basename(self.path), self.start_error_message)
selenium.common.exceptions.WebDriverException: Message: 'chromedriver.exe' executable may have wrong permissions. Please see https://sites.google.com/a/chromium.org/chromedriver/home
Also consider not adding this to the repo, write a detailed readMe as discussed and ask the user to download the suitable versions compatible with the selenium driver you are using - Chrome/80.0.3987.100
The scrap data is heavy i have csv files of upto 148MB which ideally I shouldn’t be pulling this to test your MR, I just need the link(urls) and test against the code to see if it works on my end, merging to the master branch will handle downloads of the data. We have discussed this severally!
Consider adding a detailed README!. If you need help with the Mac OS installation guide I can chime in since you are working on windows I presume.
Always check if directory/files exists or create them if not before writing data to them
@Darshpreet2000 this is GREAT, The repo is looking much more cleaner and saner without the data/CMD, and also the selenium works cool. I love it! The readme needs a lot of improvements still, don’t forget to document every step and also troubleshooting is also important.
You may want to add this to the troubleshooting for macOS users to allow permissions manually. Or they can install the driver using brew cask install chromedriver
Good job. As for the pipeline, I am sure it should be a permission issue. Maybe posting more errors on what you got, I may be of help. As for the GUI, that can happen after the GSoC or after the main objectives are attained here, keep processing the file (py) as you are doing currently. It wont hurt. I am rather thinking of an inbuilt REST server, maybe flask to test the points locally with the app. That will be discussed later for now focus on making the pipeline work and feel free to ping should you run into any errors.
Processing the files works but I get this error on the New york -
Saving
Traceback (most recent call last):
File "Process CDM/Indiana/process.py", line 7, in <module>
import pypyodbc
ModuleNotFoundError: No module named 'pypyodbc'
No Data Found For /Users/muarachmann/Documents/open_source/LibreHealth/lh-toolkit-cost-of-care-app-data-scraper/Data/New York
I have completed pipeline & scraper work, We can now discuss about the REST server with Flask needed for app, I am ready to make it. Please give its detail
I don’t think you need a complex GUI for the scraper. More important to focus on the mobile app, and building it with unit tests, so that it can be releasable into the iOS and Google Play Stores at the end of the summer.
I am in complete aggreement, the idea is just to make the scraper work, we don’t need a complex GUI or even a GUI at all actually. I’ve written stuff to automate boring tasks, a GUI is almost never needed for it, or if it is, just make it a crude UI – just enough to get the work done, no need for snazziness. If it distracts from the main project, it’s useless as we need that data, but it’s not the project itself.
@r0bby, @sunbiz I am going for an initial merge, the MRs are heavy and base for the projects have been laid properly. Subsequent reviews will be easier. Let me know your thoughts
@muarachmann – ultimately – I’m the big picture guy making sure we get all the required evaluations done and that students are on-track. I 100% trust your judgement, do whatever you feel is right.
I see it is triggered only on build? I am about to make a PR to the develop branch from master will this pull data in there, did you consider the pipeline to only run on master ?