Yeah the anti-spam measures flagged some of your posts because you shared your GitHub so much…
I understand @pri2si17, I am continuously working to improve my code, read a lot of papers and still trying to optimize the code. It seems the best way to improve for now would be more data or some data augmentation. As an ambitious effort, I am also trying to understand the AlphaFold model to predict the protein structures. I just wanted to ask if the POC which I have as a Git repository, should I try to improve it further or should I pursue the AlphaFold Model. Training and implementing AlphaFold is a Data intensive task, so I mostly use the cloud platform for everything, as the datasets ranges in 1-2 TB. I really hope you could provide me with your insights for this. Here is the Github link for faster reference:
This is simply one of the best implementations I have found so far.
I have also started working on a great visually appealing UI for the Users. I hope to complete these jobs concurrently.
And given the current Covid-19 situation, I believe this project is really important for the community.
Hello mentors, I have been working on the POC and I would like to put forth some of my results. I took up the NIH Chest-XRay8 dataset which consists of 8 classes of diseases. The dataset has over 112,000 images out of which bounding box co-ordinates are available for less than 1000 images. Here is the dataset link - https://nihcc.app.box.com/v/ChestXray-NIHCC/
Given the limitation of the number of observable samples over 8 classes, it is was not practical to apply deep learning models. There are enough samples to train a classifier but not enough samples to learn bounding boxes from.
To quote the paper - https://arxiv.org/pdf/1705.02315.pdf
Although the total number of B-Box annotations (1,600 instances) is relatively small compared to the entire dataset, it may be still sufficient to get a reasonable estimate on how the proposed framework performs on the weakly-supervised disease localization task.
If we look at the evaluation metrics present in their paper, the Accuracy is poor and Average False Positive (AFP) error is high.
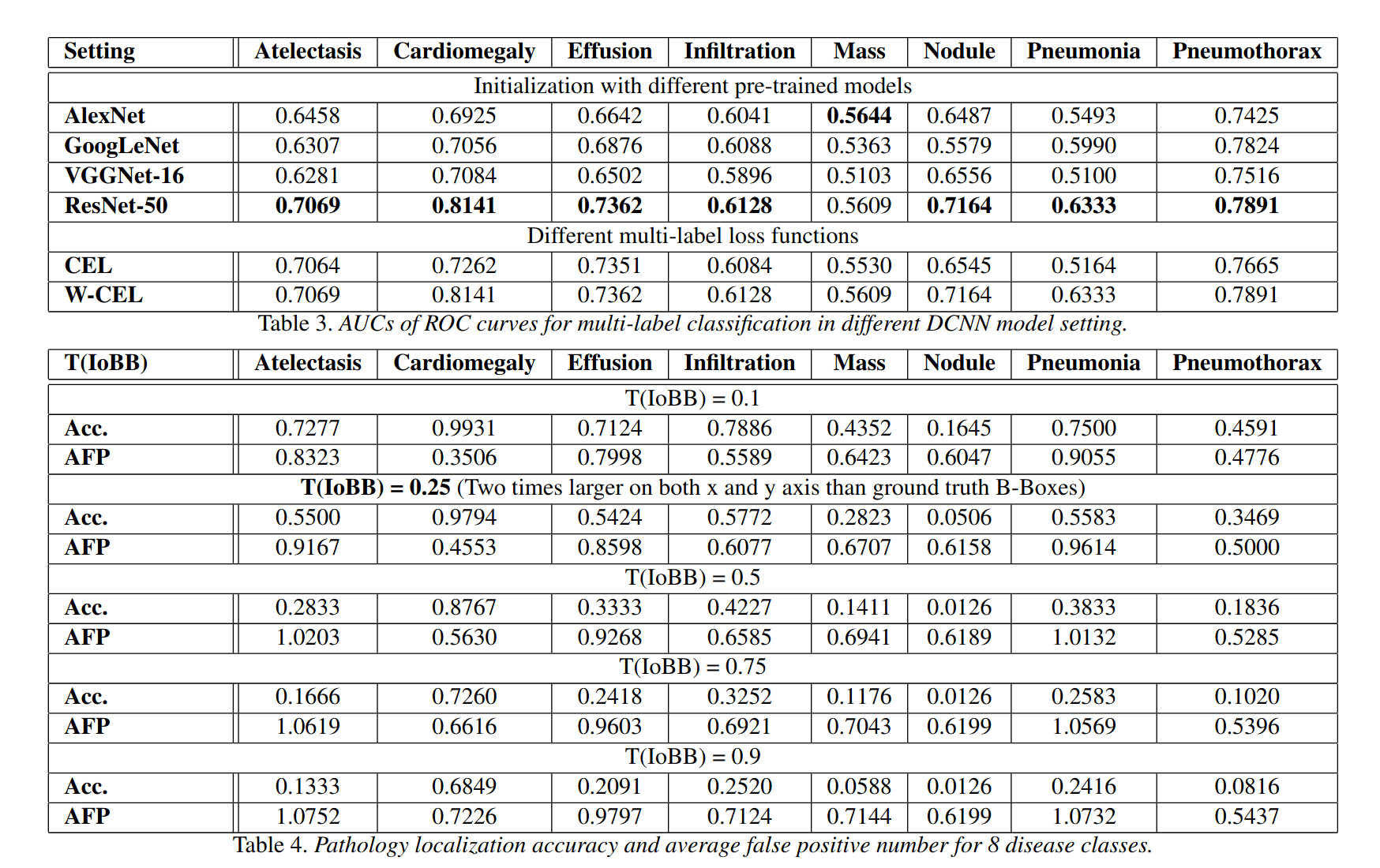
Another factor mentioned by them is that -
Due to the relatively low spatial resolution of heatmaps (32×32) in contrast to the original image dimensions (1024×1024), the computed B-Boxes are often larger than the according GT B-Boxes.
Again, if we look at the visualizations, they present a very poor performance.
The ground truth and predicted boxes do not match. Such a model is not suitable for deployment because if a patient gets such inaccurate results over diagnosis, the repercussions will be serious.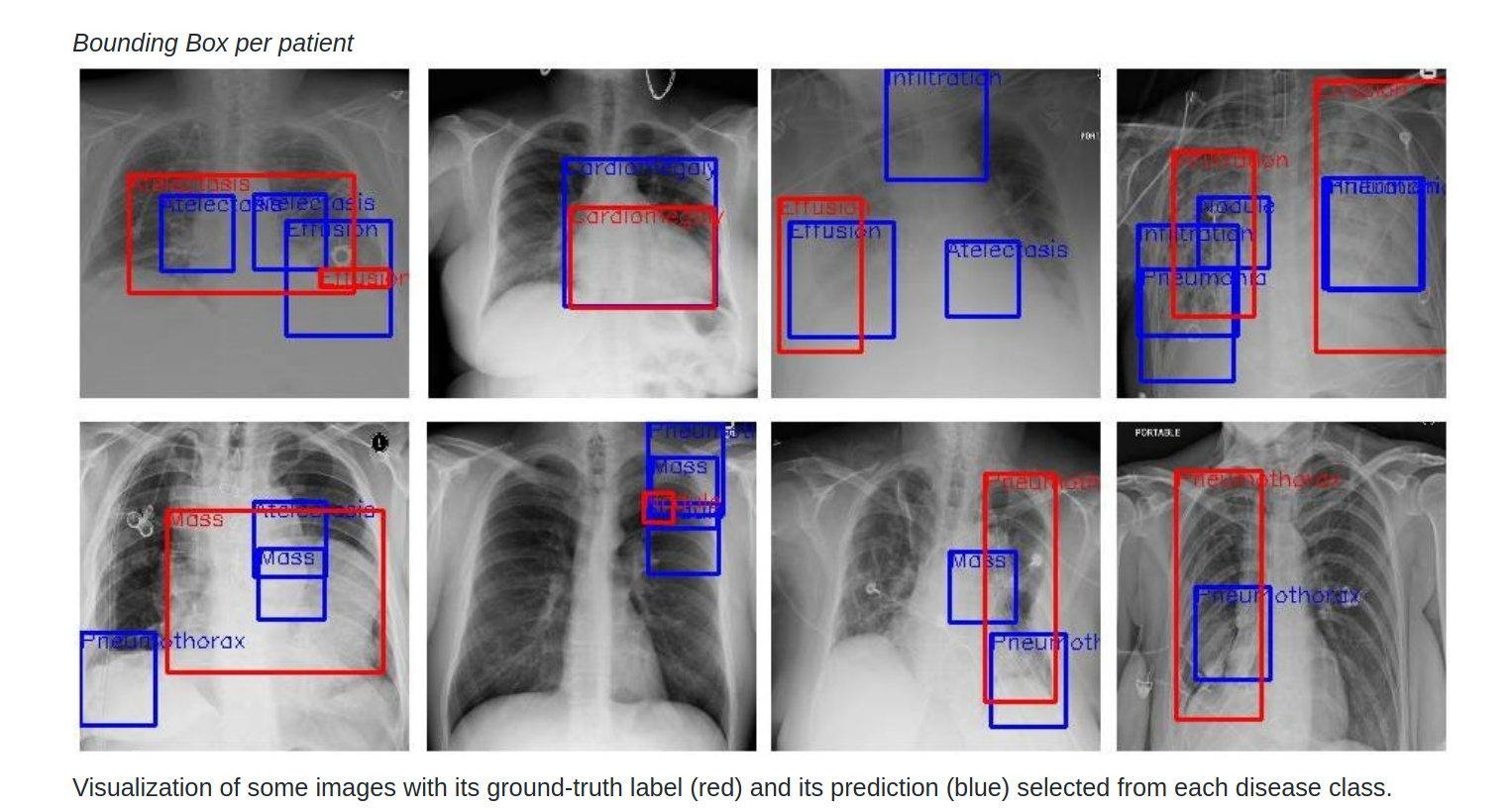
However, I still went forward and trained 2 types of models over them - Classification with localization and Object Detection models.
Classification with localization - I implemented an SSD Mobilenet model and tweaked it to output 5 parameters - 1 class label and 4 regression parameters of the bounding box. This model gave a fairly well IoU, however the loss was very high. So this model did not perform well on the test dataset.
Object Detection model - I implemented a Faster-RCNN model on the dataset. I tried this using the Tensorflow Object Detection API. This model gave a low loss but failed to give a substantial IoU to show bounding boxes over the images. There exists 1 more problem here. I implemented this using Tensorflow 1.14 and Tensorflow 2.1. Currently, Tensorflow is migrating from 1.x to 2.x. The code base has not been fully updated to support the Object Detection API and hence, there exist a lot of unresolved issues with the dependencies. Link to the API - https://github.com/tensorflow/models/tree/master/research/object_detection To train Object Detection models on this, one would have to write the complete python code instead of using the available API and this would not be completed in time to be submitted as the POC.
I have a few solutions to these problems -
-
Data augmentation - We could augment the number of samples with bounding boxes for the models to show better performance. But there remains a question of if this model will be able to generalize well.
-
Replacing bounding boxes with techniques such as LIME Explainer, GradCam, Concept Activation vectors, Saliency maps etc. - For this, we simply need to train a classification model and then apply these techniques over the trained models. They give us a visualization of where the model is focusing in an image while making classifications. It gives us segments of the image where the disease is predicted. Therefore, the advantage here is that we are not limited by the rectangular shape of the bounding box and we get more focused localization of the disease.
Please give your opinion on this and correct me if anything that I have stated above is incorrect. Also, my question to you is that may I show a POC on some other dataset with only classification applied on it as a representation of my knowledge?
@pri2si17 I have made the POC and pushed the code to github, here are few screenshots of the POC. I’m learning how to use Docker(as I have no experience in that) so I’ll surely update that shortly. All the code is in latest tf 2.1.0. The backend is in django and the frontend is in React.
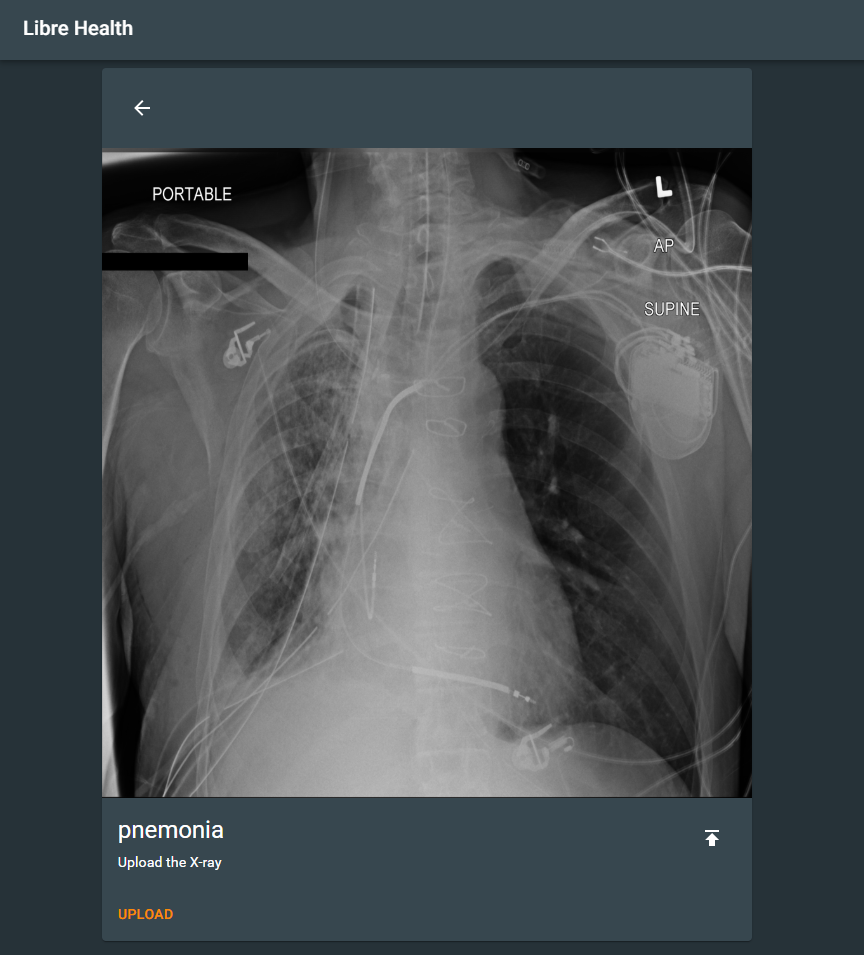
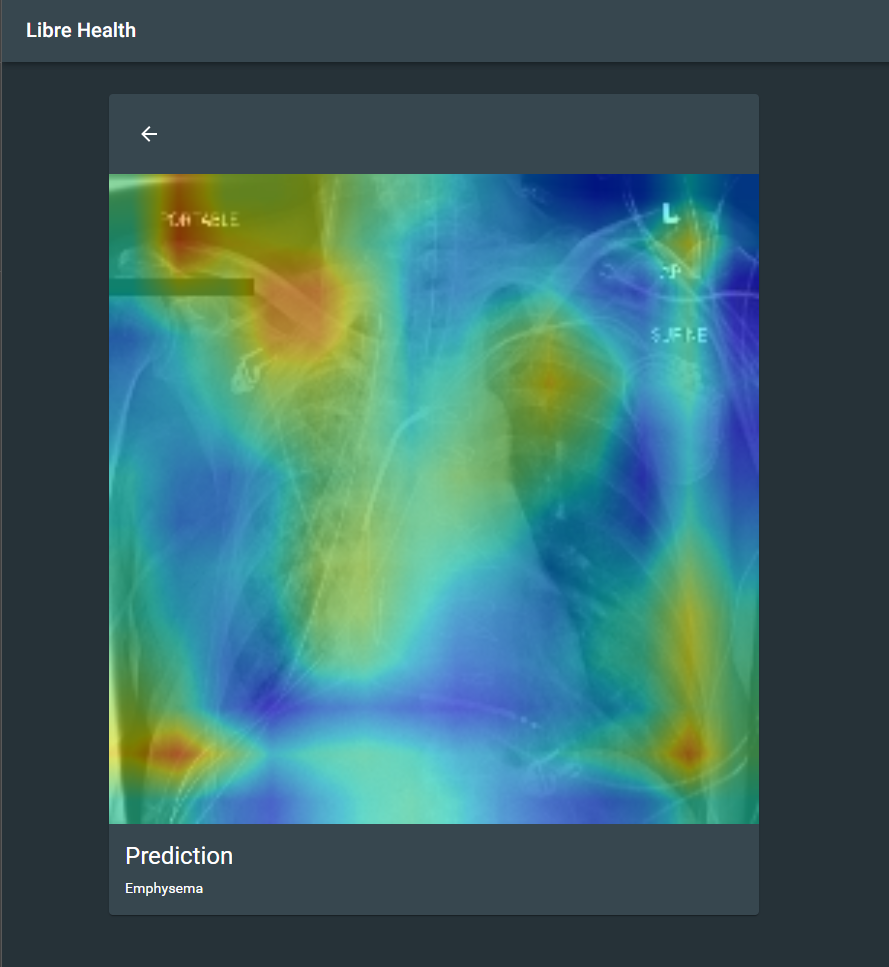
Hello @r0bby @pri2si17 @sunbiz , I have submitted the draft proposal on the Gsoc Dashboard. I would be glad to get your insights on the proposal. Please do let me know what the proposal lacks or what doesn’t meet the requirements. Please do suggest any edits, I will try to complete them as soon as possible. Sorry to bother you with a slightly long proposal but I feel these things should be mentioned as this is research based project. Please do let me know if I should shorten it or modify it in any way. Eagerly waiting for your feedback.
Hi @SinghKislay, do you have implementation of BBox as well? I will look into your code and get back to you. Till then you can learn and docker and start working on your proposal.
Yeah I will check that. Give me some time.
1 Like
Hi @aishwhereya,
You can still apply transfer learning. We need to see your coding skills, results may not be that much better, but also it will not be very worse.
I don’t see any problem here. You have other libraries available if not tensorflow. And in tensorflow also, this is not a problem. Current version is backward compatible and also you can change some of the methods to work.
What is the difference between Classification with localization and object detection?
You need to show some of your code work, we cannot judge just on the basis of proposal.
Hello @pri2si17
Yes I have used transfer learning itself. There are issues with the backward compatibility of tensorflow and I am trying to understand it better so as to make it work. I plan on showing you classification for the POC for now.
Difference between Classification with Localization and Object Detection - In Localization, you predict only 1 bounding box in the image as you have to localize only 1 object present in the image. But in Object Detection, you predict multiple bounding boxes as there are multiple objects in the image.
The second difference is in the architecture. For Localization, you simple extend generic classification models such as VGG, Resnet etc with a few more layers to predict the co-ordinates of the BBox. On the other hand, in Object Detection, you use standard models such as Faster RCNN, YOLO etc to predict the BBox.
So as per the dataset and the your requirement, different sets of models need to be used.
I have 1 more question. For this project, are we supposed to work on open source datasets or will the dataset be provided to us?
hello @pri2si17, I have not implemented bbox. I plan to implement that as well. Hopefully before the final proposal.
1 Like
Well, I think you need to get your basics correct. If you look at SSD Multibox object detector, it uses VGG as feature extractors. Object detection task itself is classification + localization.
For the datasets, I will update the post, currently you can work on any opensource dataset.
I am sorry if my terminology was a bit unclear. But yes, all object detection models have some base model as a feature extractor and then they apply concepts like RPN, ROI pooling etc. Yes, they are classification + multi object localization. I meant that for generic localization, there is a simple regressor after the feature extractor for BBox prediction. Concepts such as RPN, ROI pooling are not used. I can assure you that my basics regarding this are clear. Maybe I was not able to express myself clearly to get the message across to you.
Hi @pri2si17, is there any specific guidelines of LibreHealth regarding the text, font and color? If so, please let me know. Thank you.
Hey there,
I can answer this:
The orange: #f59031 – just use our logo – but be sure you also abide by the trademark policy.
{kind=link}
There is also a white version, which we use here on the forums.
{kind=link}
Hi @r0bby, thanks for your reply. I’m using orange. My POC and final app that I plan to make is in dark theme. Would it be too much if I did the proposal black, white and orange (basically dark themed)?
Actually, I been wanting a dark theme – if you can propose a palette – I’d love it – I’m not the best with this kind of thing.
Sure, I like doing frontend (ever since I learned react😁). I will propose a color palette as well.
This wouldn’t count for GSoC but the point of GSoC is also to get you to help out an Open Source community – it’d definately help ![]()
By the way have you seen:
Seems like it’d be right up your alley based on what you just said.
1 Like
No, I had not seen this. Had a look at it, looked at a few issues(I think I can help). I would love to contribute on the frontend. Will get to work on this after I’m done with the proposal and Docker(I have windows 10 home). I just plan to have as much open source contribution as I can this summer ![]()
1 Like