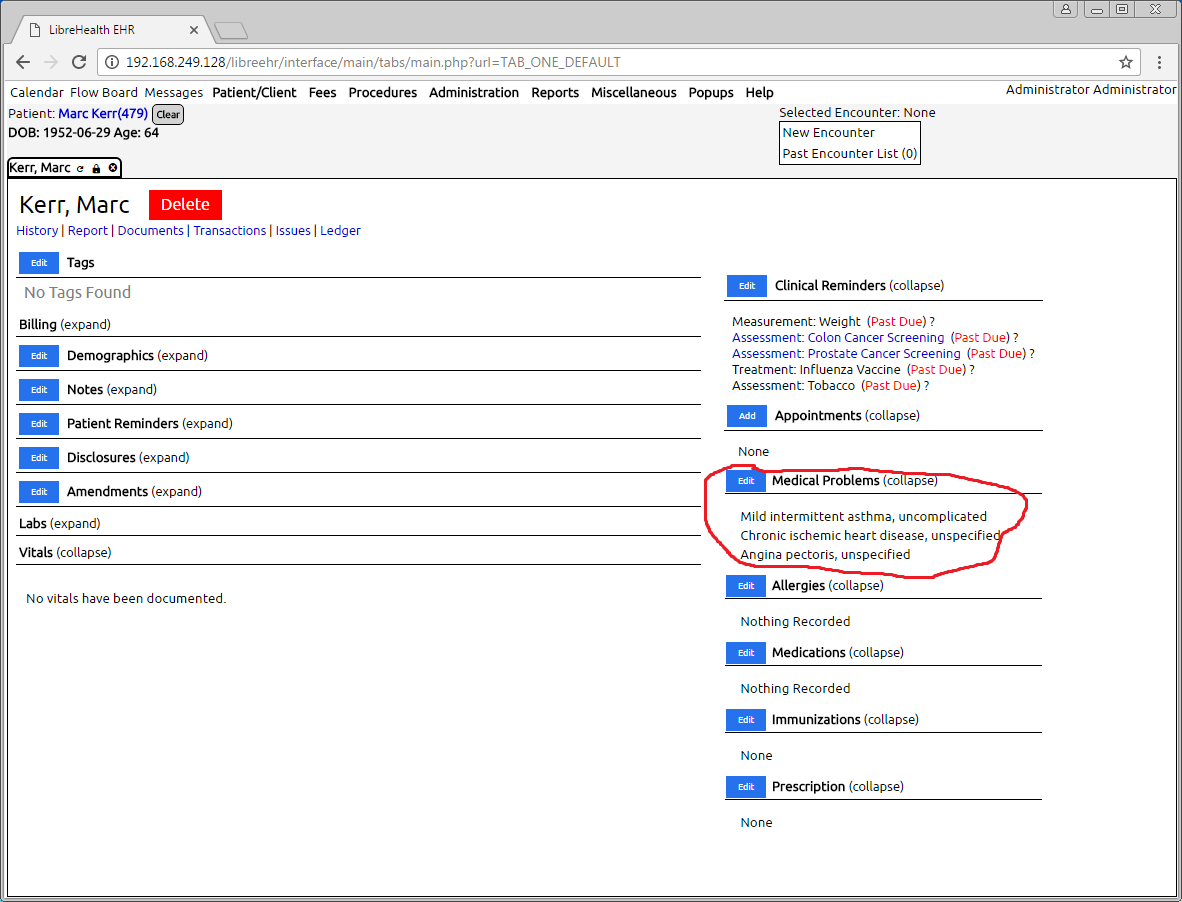
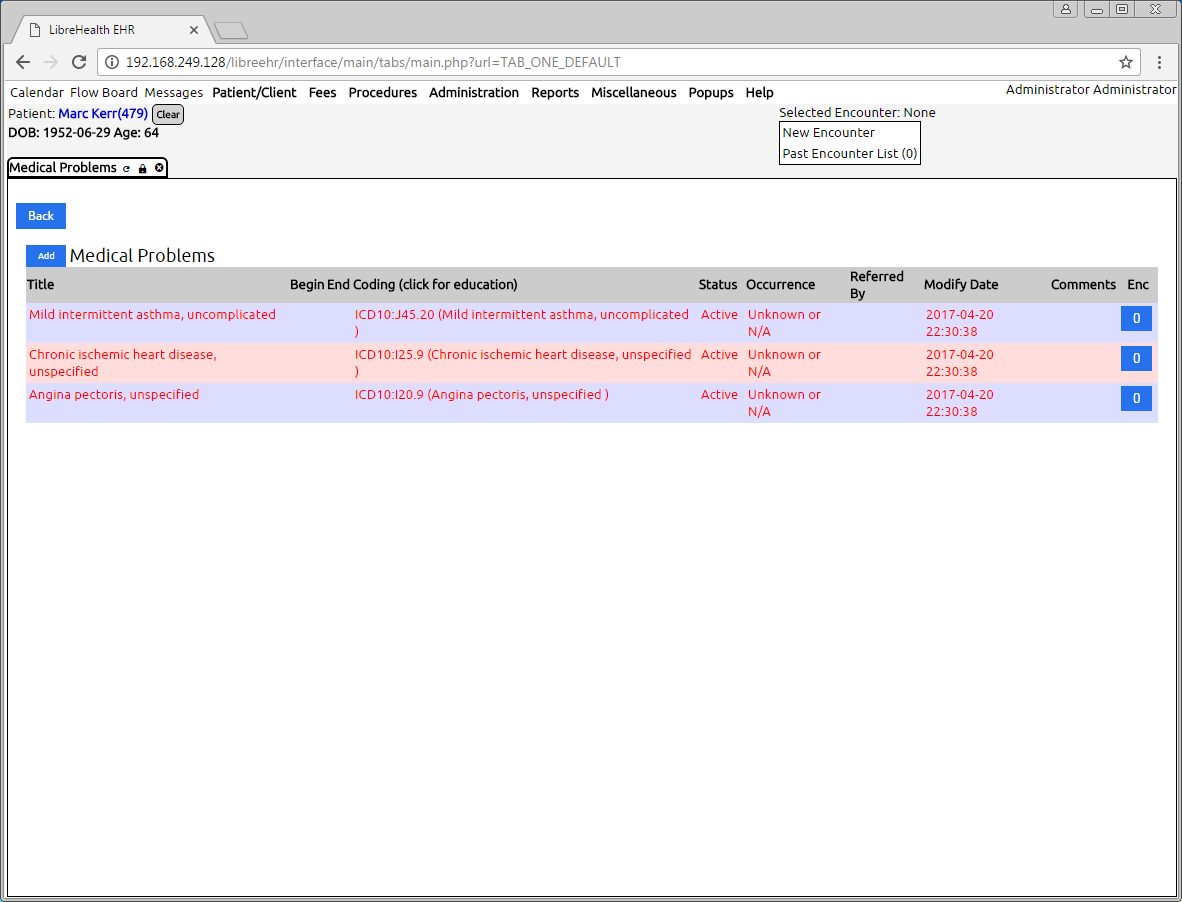
This is the new thread to discuss the status of the NHANES data project for LibreEHR. Dr. Hoyt is sponsoring this work to load NHANES data into LibreEHR for various educational purposes.
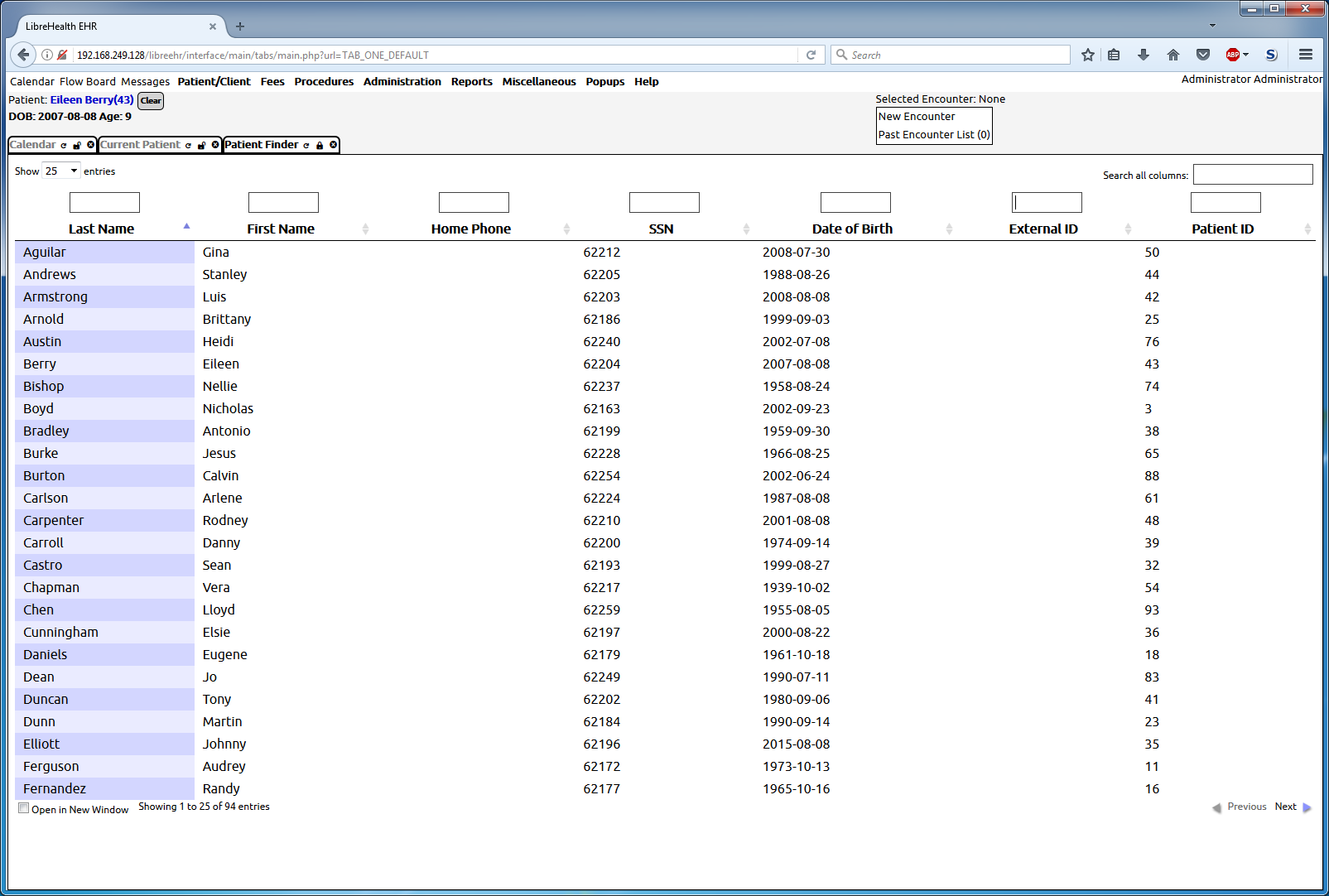
The screenshot is showing the creation of new patient records based on the demographics information from NHANES. The Date of Birth generated is based on the age reported in the NHANES files. You can’t see here the gender specified in the new records also based on the NHANES data, but you can observe the First Names are chosen from a list of the 1000 most common male or female names depending on the gender specified in NHANES, and are deterministicly generated (so re-running the script will always assign the same name to the same record.)
The “SSN” uses the seqn (survey identifier number from NHANES).
This screenshot only shows processing a subset of the NHANES entries, but I have tested with the full ~10K rows a few times.
With the creation of the base records working, can move on to filling in more of the record (problems/diagnoses, medications, etc…)
For those interested in the design aspects, the records are being generated as http requests to a running instance of LibreEHR. There is a form POST being done for each record. It doesn’t exercise the html/javascript side of the application, but it does test the PHP on the server side.
Fantastic job!!!
I am waiting on Tony’s steering committee to make up their mind regarding funding, as I am ready to go now. We should brainstorm how we can create a few slides for the inSpire conference in June that would be educational, but with a WOW factor. LibreHealth EHR has a lot of reports and I wrote all of them down, so perhaps we can generate a few interesting ones, once the database is populated with more data
Question to the software engineer types working on the project. How difficult is it to have a system audit log for functions? Instructors are discussing measuring how quickly students carry out EHR assignments and so forth. Years ago, I wrote an article on EHR usability solely based on the fact that Practice Fusion had a visible log for every function. For example, “rhoyt accessed order entry at 19:30 on 4/13/2017, ordered Ibuprofen at 19:31, exited order entry at 19:33”. Just a thought
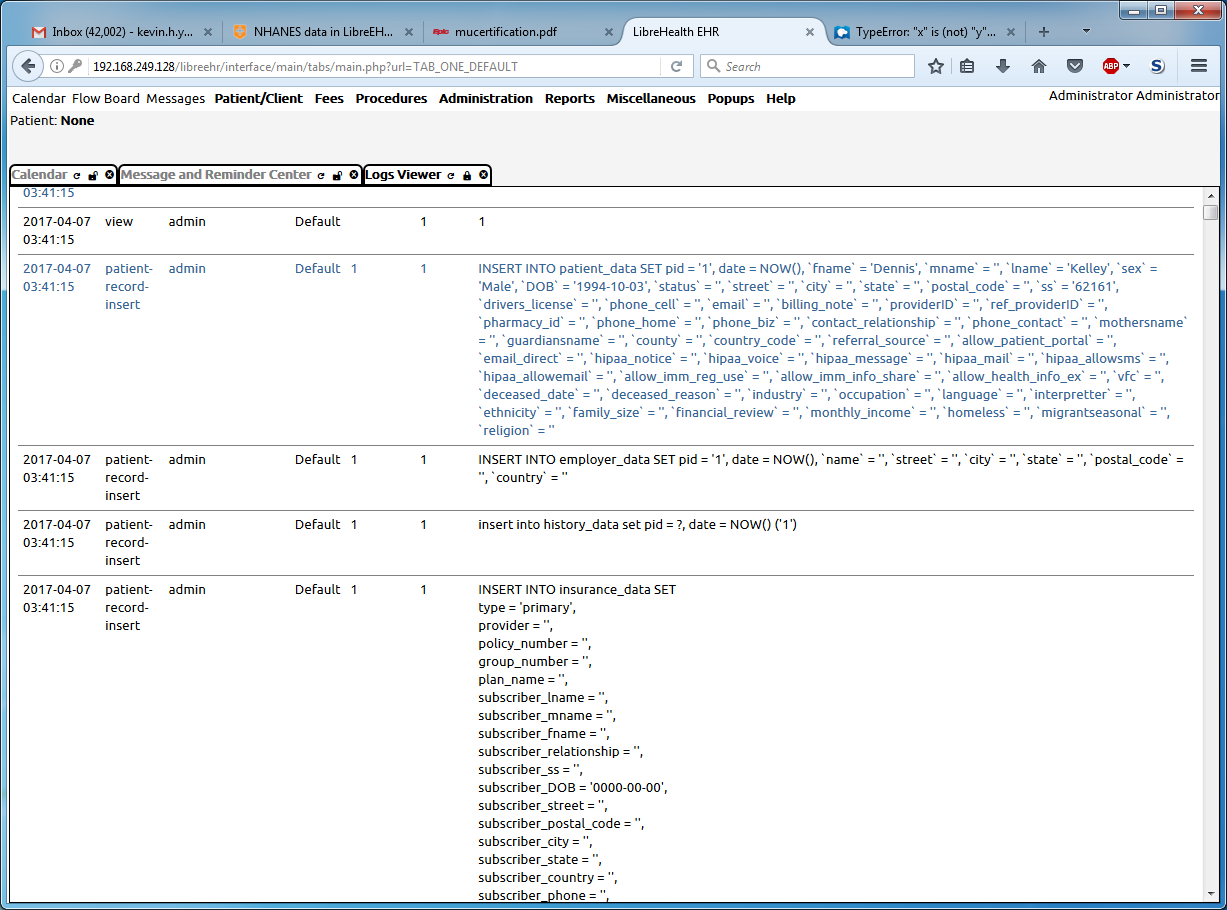
It’s not as easily human readable as that, but LibreEHR has a log which records every database access in the system. It records the query executed, user, timestamp as well as a few other bits of information.
The existing functionality might be sufficient, but it could certainly be improved.
I’ll pull some sample records to show a little later.
We have a planned redux of this feature. Part of the plan is to store the queries in their own field instead of including them in a string containing other data in log_comments to allow for better data restoration etc… so this would be the time to look at this issue/feature and offer commentary.
Here an example of the log entries from when I created the patient list using my new tool. The basic problem is it’s hard to understand exactly what operation happened because the main “content” is the SQL query. Something that might make sense is to add another column that shows part of the php call stack, so a better idea of what operation truly took place would be more obvious.
@tony I would like to setup a demo site soon. In the previous thread, you mentioned that there were AWS resources available. What would I need to do to get access?
That would be @r0bby that can help you. Do you have a pull request for us to base the demo on?
We have rackspace resources available:
See the following:
Though I do wonder if we can load this data into the EHR demo site… the less servers, the better.
No, the new project work doesn’t change any of the existing EHR codebase. It’s a separate set of scripts. (Something akin to the scripts that used to live in the contrib directory.) I will create a new github project so people can take a look at the code later.
I can setup a parallel instance on the existing LibreEHR demo server. I created a gitlab issue request.
Not going to give access – I will load the data and set up another demo though!
We have access to $2,000/month worth of credits for rackspace-- we’re barely scraping $250 - I haven’t actually done accounting…which is why everything is being moved there.
Ah, you need access…I could give that…wasn’t sure why you needed it…I can give you access.
In the near term, I’d like to be able to wipe and reload the data fairly frequently as we add to the data set. Longer term, we’re going to look at connecting Weka to the EHR’s MySQL Instance for data mining. Not sure exactly what that will entail and will figure things out locally first.
The current MySQL dump is 75MB uncompressed and 6MB gzip’d. Both will continue to grow in size.
Let me know what you need.