I think we should start with simply having these as JSON on the filesystem or Derby as BLOBs as the first pass. Have you looked at the Spring data Reactive Repository and what I mentioned about it a few posts back? I think we should go for this, if others in the community think its a good direction. Going back to a relational database after getting such nice document-like representation of FHIR doesn’t make sense to me.
Small microservices with reactive data access should be the way to go. I think its time to go Reactive, since we will move to a new data model.
@sunbiz I will look at the spring data reactive and update.
Saving JSON representation straightaway to the database would be fine in the first phase. In the long run, there will be resources that is getting referred within other resources. Also search capabilities needs to be added which might require to separate the data.
Note that “encounter” is the term used in our EHR as well as most other recently developed systems. It might be worth shifting the toolkit terms for this basic concepts. Encounter/D.O.S./MRN vs. Appointment. Visit is a bit too ambiguous. We only recently converted to that paradigm ourselves. It is actually a very helpful distinction in training and development.
@sunbiz I had look at the spring reactive. MongoDB and Cassandra are most popular No-SQL databases which supported. However spring data reactive is at early stages.
Also with this project are we going to create separate web component from scratch or are we going to integrate the capability inside the current code base?
We should probably start from scratch, but use as much as we can from the present toolkit. I am not very sure of the answer yet.
@prashadi , how do you feel about working on an analytics engine of the JSON documents? Something that might use Apache Spark on Cassandra? So the FHIR JSON will be used to run over Spark?
That’s also fine. You mean extracting useful analytic data or summarizations of FHIR JSON documents using spark? This to look for the capability of how FHIR suites for analytics?
I have, although in its early stages, I like how the implementation is really similar to relational repository interfaces. If we don’t need pagination, it seems like a viable way to go. I like the non block rxJava like data types too.
I stand corrected, albeit pagination support inbuilt is not very mature, pagination can still be enabled quite easily by manually specifying method signatures with pageable parameters in repository interfaces.
Yea, I don’t see why pagination will be a problem if you can subscribe and not wait for it. I think it’s pretty mature and trivial to do. See examples - GitHub - MavoCz/spring-webclient-reactor-test . It will be nice if you can create a starter project, and expand your patient-filter to use Reactor instead of JPA.
This is awesome. Exactly what I was thinking we should be doing. I am glad Cerner even open-sourced it using the APL2 license for us to use. The FHIREncoders are nice, and I had a similar pattern when I was thinking about it. As part of the GSoC project we should use it and build a UI around it, along with writing any connectors to Ontologies to be able to use dictionary like CIEL. @prashadi, Can you please test it on Google Test Data, and let us know how it performs? Just take the JSON and not the proto formatted ones.
@sunbiz I have implemented reactive programming with mongodb in the reactive branch of my task. Please note the fhir server I have specified in the properties does not seem to be working correctly, so I reduced the no. of patients, encounters and observations but feel free to edit them in application.properties (fhir.data.*.count).
@sunbiz I have checked on the Bensen library and its functionality. It’s looking great. First I have setup the spark which is a per-requisit for the Bensen. Then I have looked at the core APIs. Currently Bensen provides capability to imports the bundles to the system. When I checked the google test data set, most of the sample data are resources. So we will require to convert resources into the bundle first before do any analysis. Because of that I have tried SMART test data set in generated-sample-data/STU-3/SMART at master · smart-on-fhir/generated-sample-data · GitHub. I was able to perform queries on top of data. So spark allow to query based on multiple attributes.
I imported data into the spark as follow.
from bunsen.bundles import load_from_directory, extract_entry
bundles = load_from_directory(spark, ‘/home/kavindya/generated-sample-data/STU-3/SMART’)
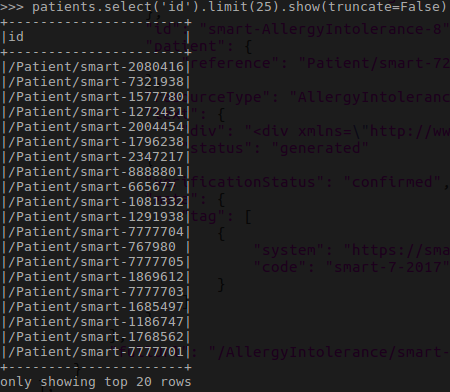
Then I ran follow code to extract patients
patients = extract_entry(spark, bundles, ‘patient’).cache()
Then operations of patients can be perform as follow.
This is mainly based on the python. But we can utilize the Java API to build anything top of it.
@sunbiz would you like to do any further testing on this?